


Introduction
Welcome to the second part of rapid application development using LLMs, specifically the LLM from Vertex AI. If you missed the first part where we laid the groundwork, I’d suggest giving it a look for a step-by-step walkthrough.
Now that we have successfully built a PoC within just a couple of days, we could call it a day and break out the celebration snacks. However, we are not settling for the basics — we are here to wow users.
So, what steps can we take to transform the project from a PoC into a robust MVP?
Here are some cool features to add:
- 1. A user-friendly front-end to allow people to directly test the solution.
- 2. Persistence of files with metadata.
- 3. Persistence of the results in a database.
To achieve this, we can leverage various tools offered by Google Cloud Platform (GCP). I’ll provide a more high-level overview and propose a comprehensive architecture for your consideration.
Front-end to befriend users
I find my comfort in numbers, in the black screen with a blinking cursor – deep in the stack. So I’ll be honest with you, front-end development isn’t my strong suit. I’ve given it a shot before, but the entire process doesn’t resonate with me – the tools, the languages, it’s just not my cup of tea.
P.S. However, I have immense respect for those who excel in coding and design.
Since I needed a quick front-end solution, I turned to my now-close friend, Vertex AI. Leveraging code-bison, I tasked it with crafting a sleek frontend for me, using the following prompt:
I need a single html and js page with bootstrap that has a form to send a pdf file to https:///law_proceedings with the key "law_file", then it should display the file and wait for the response. after that display the response dynamically. with cors enabled.
And here’s the result:

After that, I needed a few more prompts to get the response I wanted, including tables and even tossing in a logo as a prompt.
Then came the deployment phase. To be entirely honest with you, I probably should have opted for App Engine. However, I took a shortcut and simply pasted the code onto another Cloud Function, and to my surprise, it worked like a charm – and it’s still alive and kicking.
Persistence of files and information
Now, we’re diving into the more mundane, ERP-like segment of the project – no AI magic to rescue me this time. Let’s roll up our sleeves and get to it. Here’s the checklist:
- Save the file.
- Include some metadata.
- Store the information in a robust and flexible database/warehouse solution.
The service choice here is crystal clear. I’ll use GCS for file persistence and GBQ as the database — thanks to its limitless resources, user-friendly interface, and all-around awesomeness. For a transactional database, Cloud Firestore comes into play, enabling the front-end to query directly without experiencing GBQ lag.
As we deal with multiple moving parts, we need an effective integration tool or method. While raw API calls are an option, choosing them would mean missing some cool turn-key features available in other systems on GCP, such as retries and multiple destinations. So, I’ve opted for Pub/Sub due to its unparalleled performance, scalability, and reliability, setting it apart from any other cloud service.
As we improve the code, it makes sense to split it for better adherence to the single responsibility principle.
Thus, I devised the following architecture:
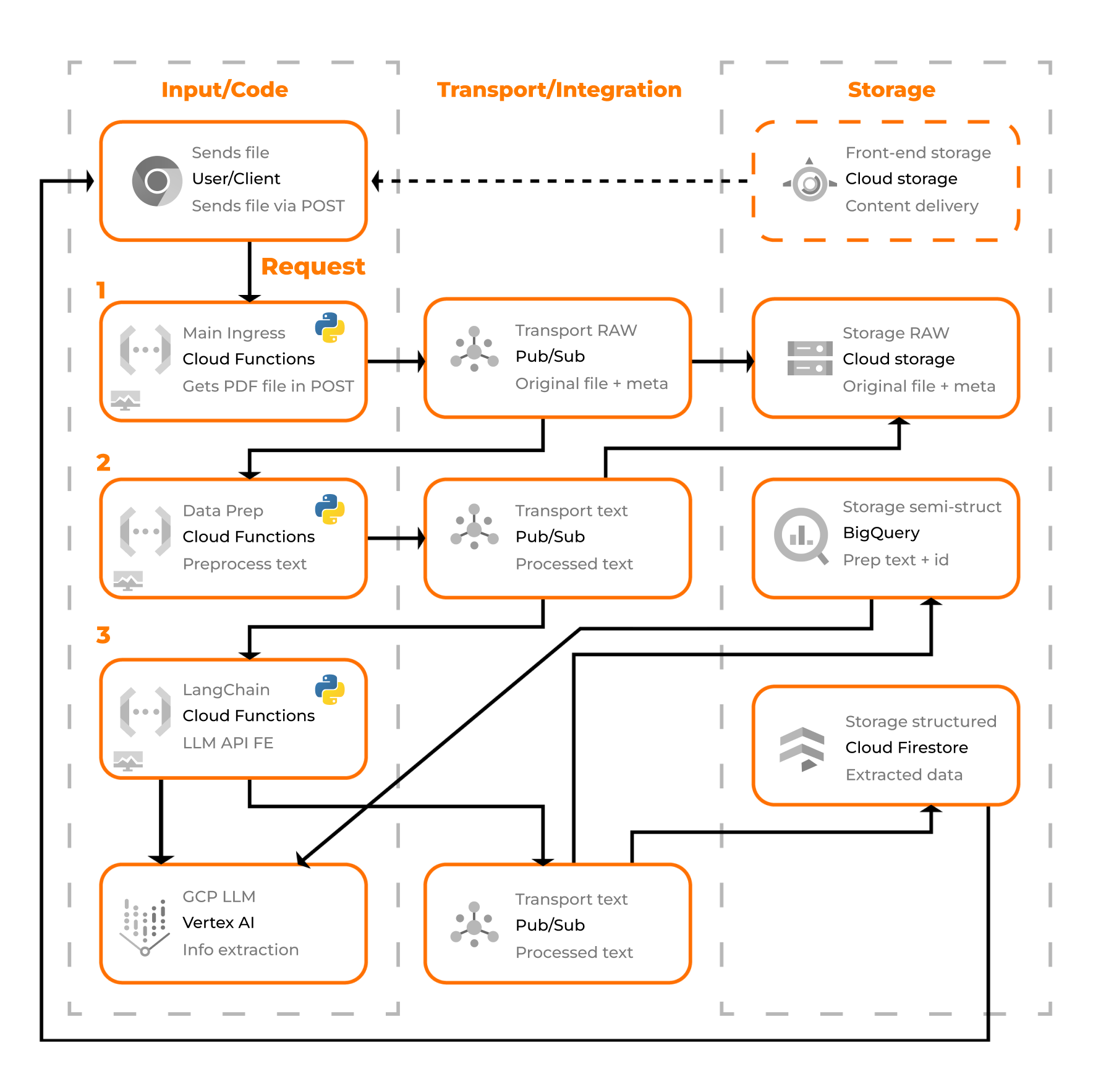
Architecture breakdown
Client communications are streamlined through a single Cloud Function. I handle the file sending (POST), and the response is the data extracted, structured as JSON. During this phase, I already persist the file using Cloud storage and send some metadata as well.
Moving to the second step, I organize the data for consumption by language frameworks such as LangChain. This involves storing the data in an unstructured format on GCS and semi-structured (TEXT) in GBQ.
In the pivotal stage, I use LangChain to efficiently handle the data and interface with GCP LLMs (text-bison) via Vertex AI. Once structured data is extracted, I persist it in GBQ and Cloud Firestore for transactional querying. This not only enhances the training mass for the model (GBQ) but also facilitates the return of data to the original caller by querying Cloud Firestore.
Considerations: all transport is done using GCP Pub/Sub, leveraging Google’s native connections to seamlessly load data onto the services. The code lives only on Cloud Functions to manage the data, so actual development time is reduced (only 3 files with approximately 80 lines of code each), leaving the developer with the sole task of sending a message to Pub/Sub.
Embracing a 100% serverless approach not only streamlines the infrastructure but also ensures high availability and scalability right from the start (scaling to ZERO = savings). In the event of any issues, whether related to cost, throughput, or even the tunability of the LLM model, we can opt for GKE-based solutions. GKE allows for greater customization and a code-based approach, with various architectures available within the GCP catalog.
It’s safe to say that we now have a robust MVP.
Implementation
Being completely in “Rapid Mode Engaged,” the solutions we have here are the epitome of turnkey. The majority of them are point-and-click, with even complex steps, such as when Pub/Sub persists to storage, being seamlessly automated by Google.
As we split the responsibility into three Cloud Functions, we can now generalize the code, laying the foundation for further development using the same concept.
This approach caters to all the requirements for a truly impressive MVP, leaving us with:
- A cool LLM implementation.
- A public API to serve and manage the system.
- A multitude of services working behind the scenes.
- A happy client.
- An exceptionally short lead time for this MVP.
Wrapping up
I must say that incorporating the LLM from Vertex AI into the development workflow has exceeded my expectations. In perspective, this technology can not only facilitate the software development process but also enable quicker and more efficient iteration between different stages. Accelerating the pace at which we can bring ideas to life, without compromising on quality, is a game-changer.




