


Introduction
Large language models (LLMs) are rapidly transforming the software development landscape, offering unprecedented capabilities for generating code, translating languages, composing various creative text formats, and answering your questions in an informative way. However, effectively integrating LLMs into the software development process can be challenging.
This article provides a practical guide for rapid app development using LLMs from Vertex AI, covering the entire process from idea to production.
Large language models (LLMs) in a nutshell
Large language models are a particular field of Machine Learning that are trained on extensive datasets of text and code and can understand, summarize, and generate human-like text.
Current large language models (LLMs) leverage the transformer architecture of neural networks, which excels in Natural Language Processing (NLP) compared to previous approaches that relied on token chains resembling time series (such as those utilizing LSTMs). When tuned for specific tasks with custom data, such models can perform various tasks, from answering specific questions (prompts) focused on relevance to summarizing complex texts and engaging in casual conversations.
There are several LLMs available for free for any developer, scientist, or just a tech-savvy curious mind. The most famous models, like ChatGPT or Google Bard, come with user-friendly interfaces and are pre-trained. They can be great assistants, but relying solely on LLMs for things demanding profound context understanding, deterministic approaches (such as in software engineering), and other crucial tasks can be risky. While LLMs can enhance human expertise, they should not serve as a complete substitute.
Rapid app development using LLMs
If you are a fan of rapid application development (RAD), LLMs can come in handy.
Quick note: RAD is employed here more as a high-level approach for rapidly developing a concept by leveraging LLMs, rather than as the entire methodology for the SLDC.
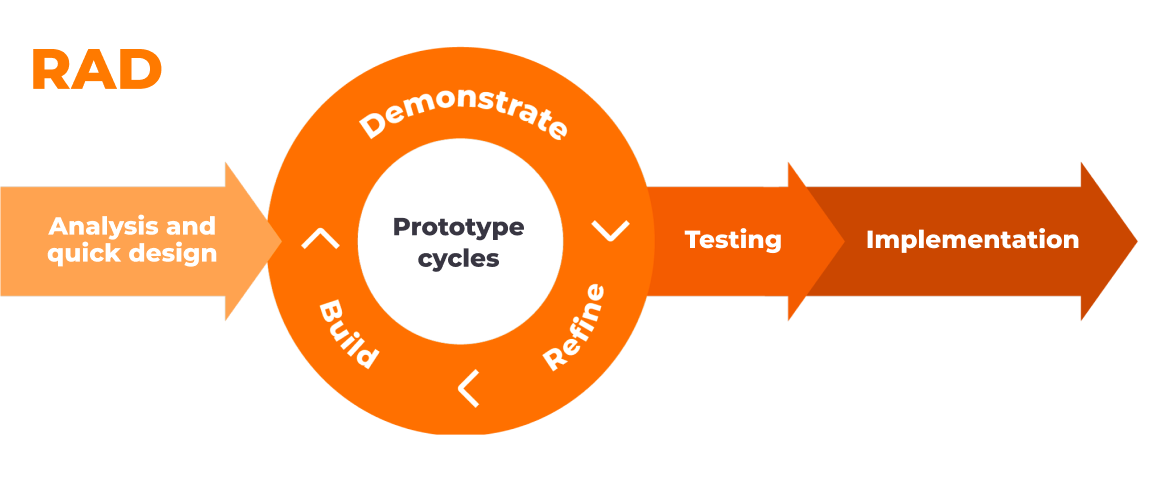
The problem
AgileEngine was approached by a client with a specific request. The company needed an application that would read legal filings on lawsuits and extract vital information (parties involved, claims, values, etc.) for later integration with its legal management software, which is fully integrated with the client’s ERP. Globally. This particular request came from the Brazilian branch of the company, with very specific requirements: all files are unstructured PDFs, and they are in Portuguese.
I could build a deterministic set of rules, text scans, etc. However, as mentioned earlier, the text is unstructured, and every legal operator has a very particular style and a language structure, and so even the order can change. Given that this is a global company, they standardize all legal proceedings to a single structure and want to scale this software to other languages. Deterministic approaches would not be effective in this context.
Another approach is using traditional NLP techniques like classification and Markov models. However, the volume of information for this training and the training process itself (mostly human interaction) is very hard to achieve without proper investment. But if I leverage an LLM to perform this, particularly with its context and summarization capabilities, it can lead to a really fast, iterative process to deliver a product (PoC or MVP, for example) in record time. In all languages possible. With a single piece code.
I will walk you through the steps I followed to develop this in record time.
Step 1. Choose the right platform
Everything is cloud. And that’s the way it should be. Almost unlimited resources at a click’s distance. While, of course, you could take the model, take the data, and train it on your GPUs and clusters, that would take too much time and resources. The optimal solution is to find a cloud provider that meets all your needs.
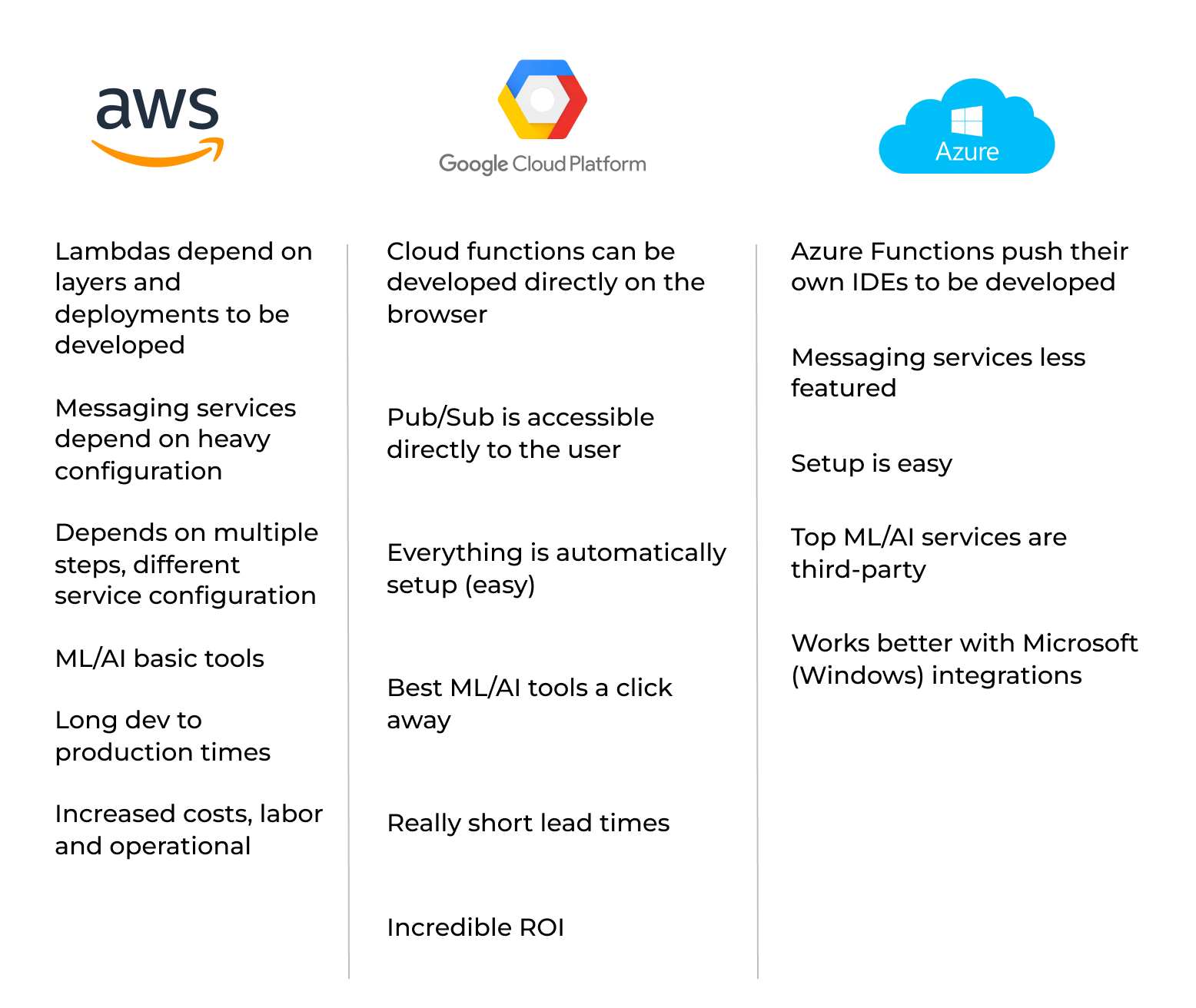
I can talk about the big three (GCP, AWS, and Azure — everything else is niche), but we need something that provides robust support for ML/AI, along with quick and easy access to develop and utilize essential tools (APIs, network, etc.).
As for the current landscape, we can rule out AWS since its ML solution focuses more on data exploration rather than actual implementation. Although Azure offers integration with ChatGPT, which is cool, developing software around the LLM can be challenging due to the need for integrations and the lack of direct support for serverless computing.
This leaves us with GCP and its Vertex AI platform that enables users to access top-notch pre-trained models with Google’s infrastructure. GCP is considered to be the easiest and most capable cloud provider out there.
So… GCP it is! Let’s set up an account (if you don’t have one), create a project, and you are basically ready to go.
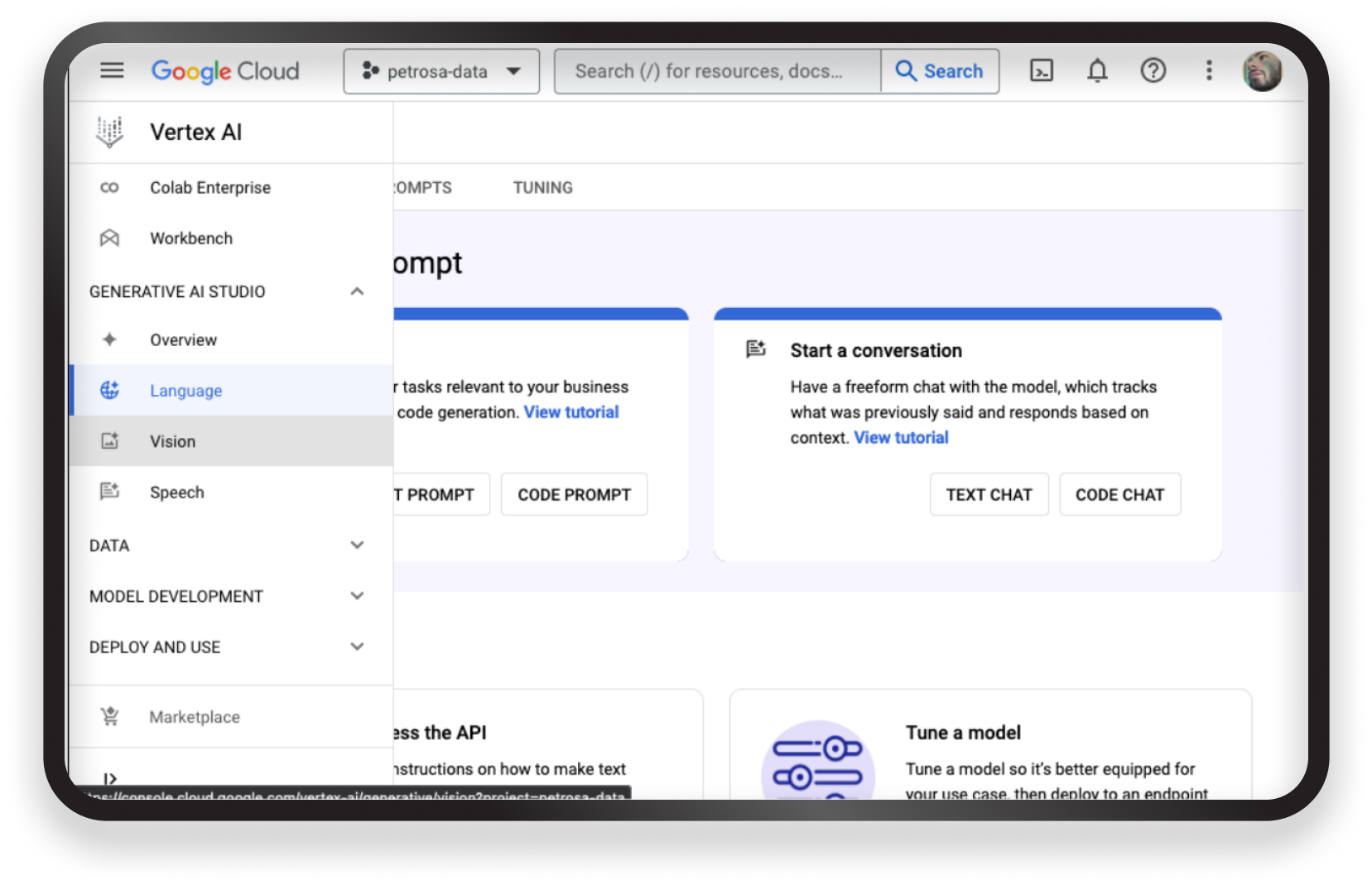
Step 2. Test a little
With our platform ready, go to the console and search for Vertex AI. Once there, you will have access to all models. Look for Generative AI Studio and click ‘Language.’ From there, proceed to the ‘Generate Text’ tab under ‘Text Prompt.’ You’ll be presented with a text box, allowing you to chat with the model right away.
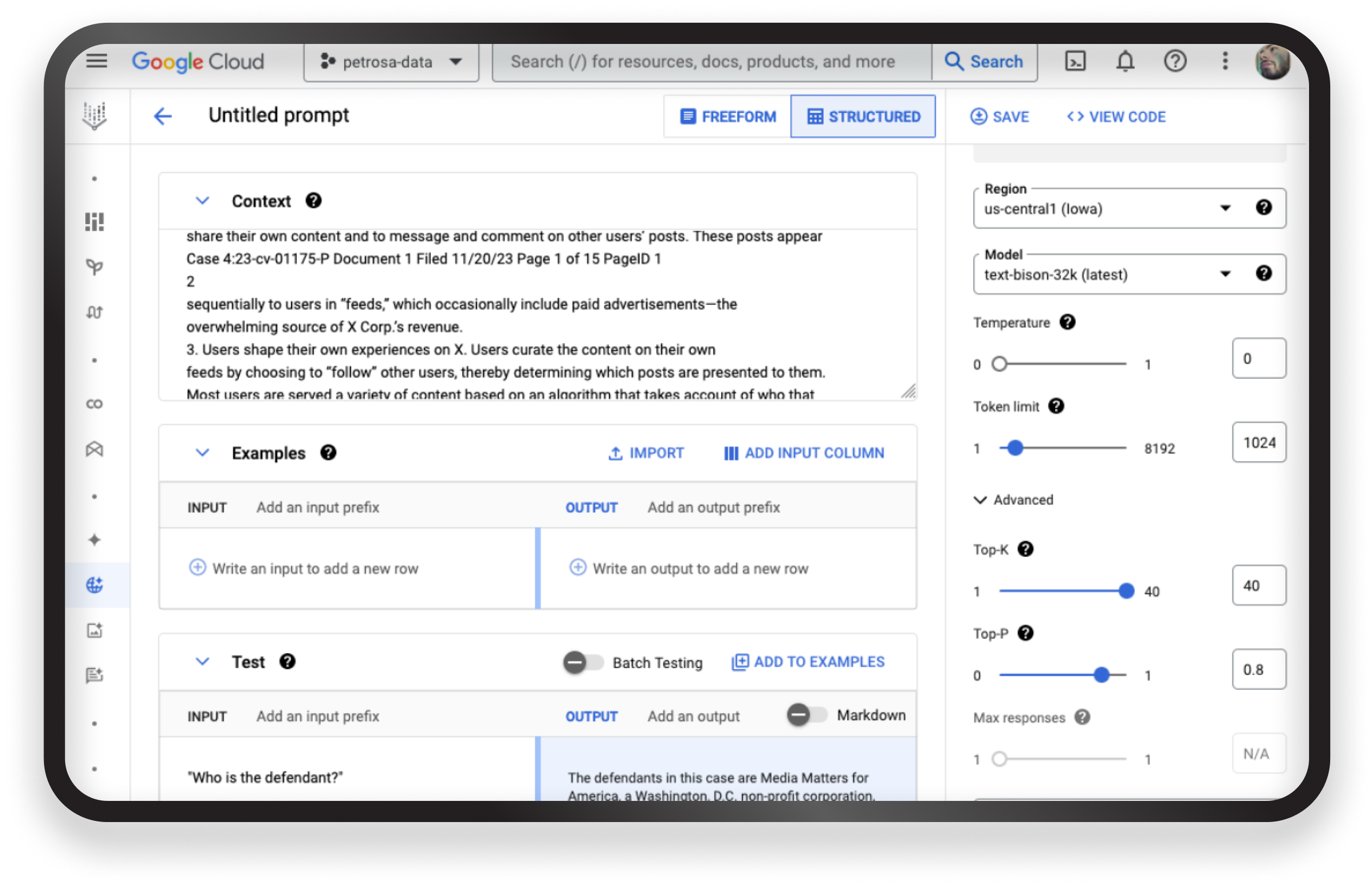
On the right pane, you can choose your settings, including the model, temperature, and other parameters. This is useful because we want to extract information, which leads to very little randomness (Temp = 0), and we have only one possible candidate since we won’t be deciding which version is best.
In our case, I just copied directly from the PDF samples, pasted the content, and started asking questions to see the level of quality we got.
Key questions included:
“Who is the plaintiff?”
“Who is the defendant?”
“What is the reason for this legal filing?”
“What is demand value?”
And guys, I have to say, it performed great. All that pre-training, model access, everything paid off. So we can move forward with our application.
Step 3. Extract raw text
Now that we have confidence in using Vertex AI and Google to extract the information we need, let’s delve into the software aspect.
We need a way to:
- 1. Read a PDF and extract raw text programmatically.
- 2. Process this text to save on tokens, discarding senseless/repeated information.
- 3. Consolidate the text and integrate the prompts you want.
- 4. Interact with Vertex AI and get results.
This is code and code only, nothing ML/AI here. We just need to process this file and actively get what we want to process.
GCP allows us to compute in many different ways, but we want to be quick, right? We don’t want to be deploying infrastructure or something like that. Opting for the Serverless route, we will deploy all of our code as Cloud Functions, a GCP product that allows seamless deployment of code pieces integrated with cloud services.
This automatically gives you a URL to interact with the function from any client (e.g., a web browser), and the tooling needed to run the code. Another thing is that you can code directly in the browser, with access to the lib repositories you want, eliminating the need for layers, zips, or IDE integration. This helps to deploy complex structures quickly.
Go to your console, search for ‘Cloud Functions’, and click on ‘Create function.’ You will be presented with some basic settings, like name and resources, change the name and authentication (strongly suggest allowing unauthenticated invocations for now); leave everything else default.
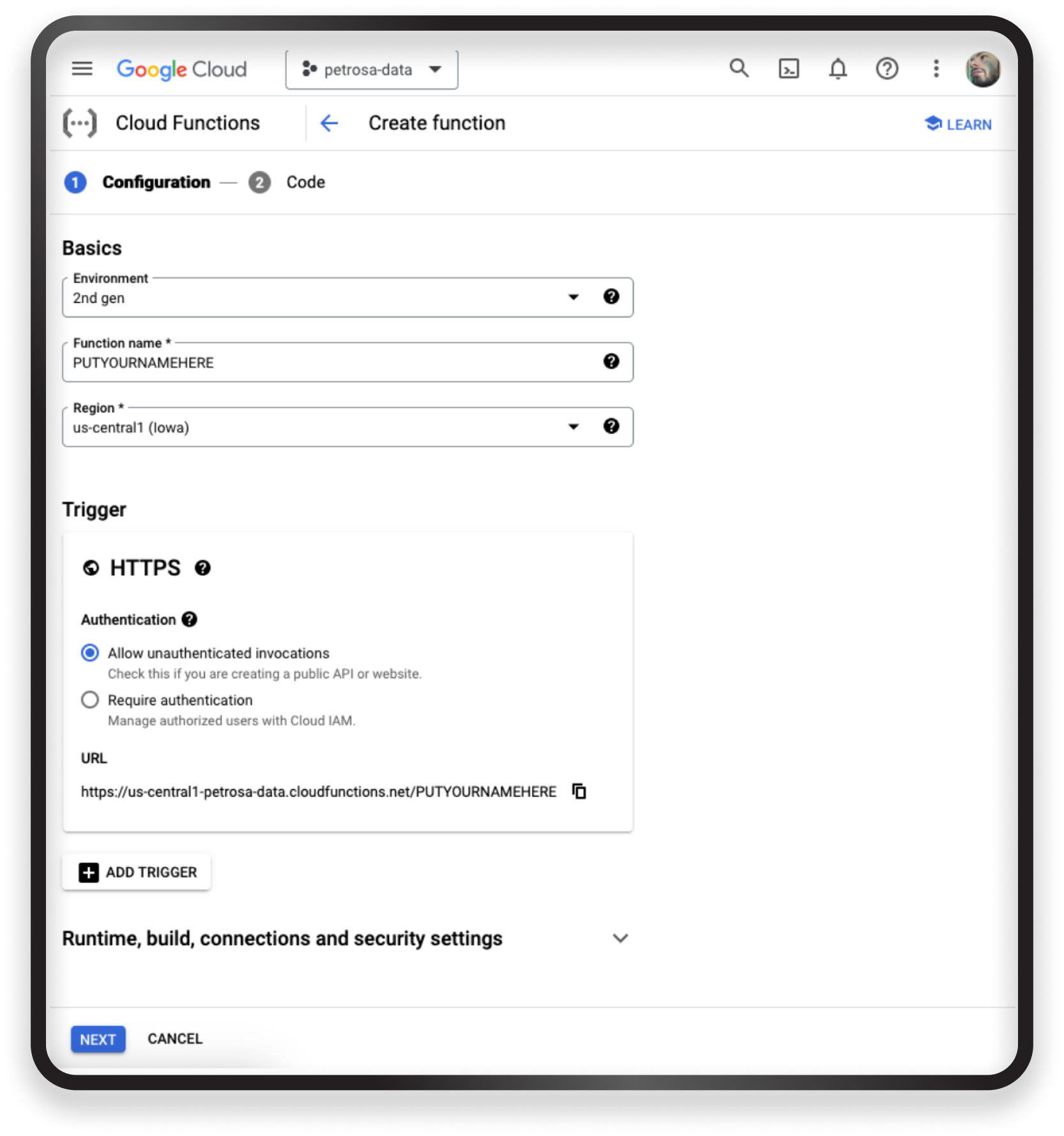
Click ‘Next.’
You will be presented with the code editor where you can choose your Runtime (language) and a template to develop upon. For this development, we opted for Python because it is closely related to ML/AI and has libraries that can easily manipulate files and texts.
Here, we just develop a simple code getting the PDF file via POST, extracting the raw text, deleting multiple repeating lines (to eliminate unwanted headers and footers), and leaving us with a single string containing all the PDF contents.
Note: We used a combination of PyPDF2 and LangChain to manage this text extraction. We can use a plethora of libs and text processing, but we chose those because of their level of support.
Now, it’s time to combine the raw string with our prompts for the LLM to process them automatically.
We used the format proposed by Vertex AI with:
context:input: prompt
So you can use basic text concatenation to merge it all.
Put this string as your return and test it, you should get the text plus your prompts.
Congratulations — we are done with the text processing!
Step 4. Send it to Vertex AI/text-bison
Now it’s time to extract the data, let’s send it to Vertex AI. Edit your Cloud Function with the following.
You just need to initialize the Vertex AI package with your options (project and location for the cloud).
Instantiate the model using the language_models (we used from_pretrained() method) package and pass your string to the object using the predict(“text+prompt”) method.
You can now get answers from the model right away.
For the prompts:
“Who is the plaintiff?”
“Who is the defendant?”
“What is the reason for this legal filing?”
“What is demand value?”
You should be getting something like:
**Plaintiff:**XXXXXX, a Nevada corporation
**Defendant:**
– XXXXXXX
– YYYYYY
**Reason for Legal Filing:**
Praesent quis tellus rutrum, tristique libero eget, ullamcorper mi. Maecenas placerat mi non justo semper pulvinar. Aenean quis imperdiet mi, ut sollicitudin velit. Interdum et malesuada fames ac ante ipsum primis in faucibus. Phasellus finibus mi arcu, et ultrices risus bibendum id
**Demand Value:**
The specific demand value is not mentioned in the provided text.
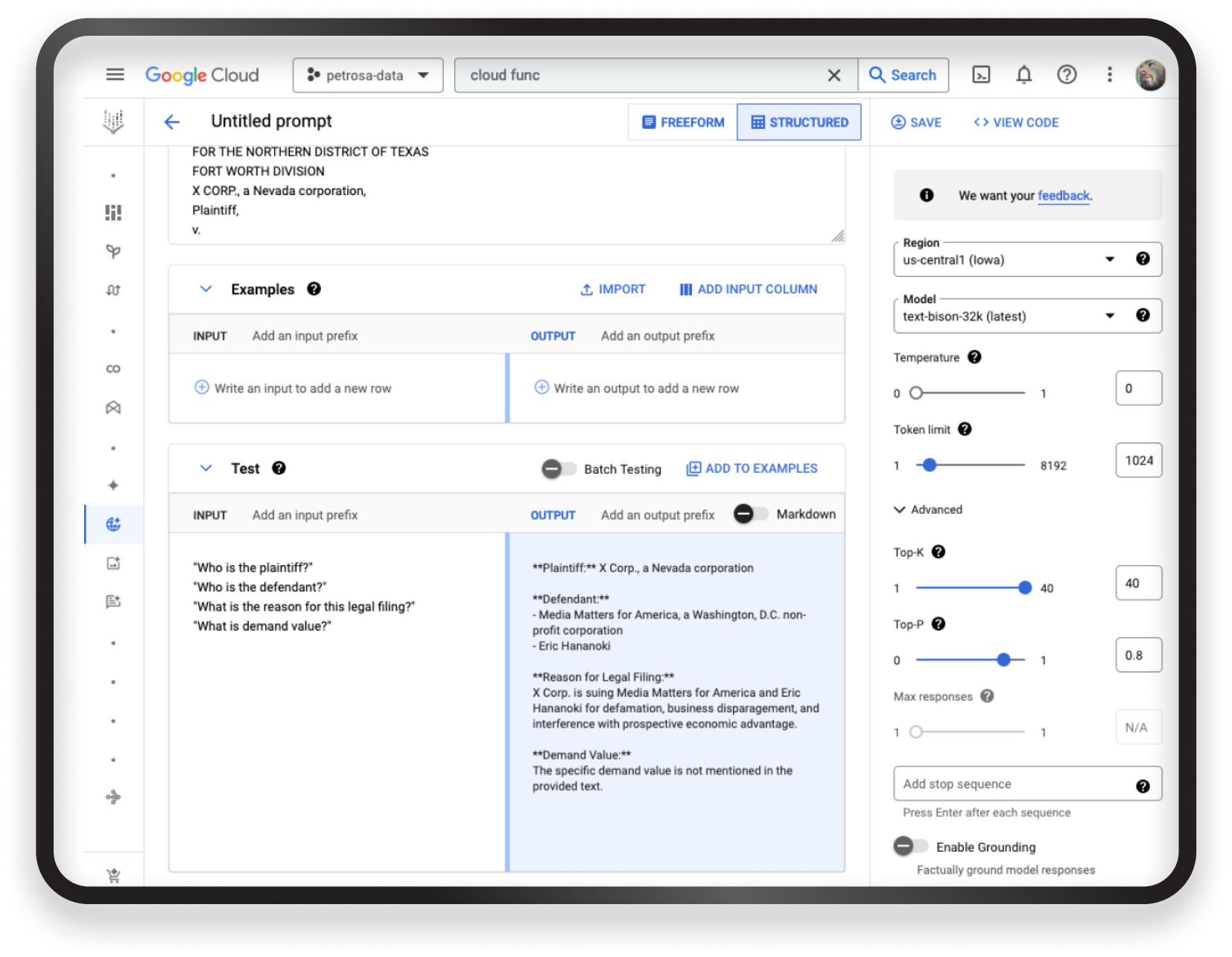
This never fails to amaze me.
Step 5. Format your output using the LLM
Now you have a Markdown text with the results of the prompts (mainstream LLMs LOVE Markdown, for whatever reason), but we can make this better. We can let the LLM do some hard work for us.
As we are on the internet, REST is a must, so we should be outputting a JSON object as a string. Then, we can seamlessly integrate with all the clients and languages out there. Instead of adopting the developer approach of taking the result, splitting it, and formatting it into JSON, I will ask Vertex AI to do it for me in my prompt.
I will include the desired format directly in my prompts, outlining the complete structure.
So my prompt will be in the format:
Answer the following questions:
"Who is the plaintiff?"
"Who is the defendant?"
"What is the reason for this legal filing?" "
What is demand value?"
In JSON using the following format:
{
"plaintiff": "string",
"defendant": "list[str]",
"reason": "list[str]",
"value": "number",
}
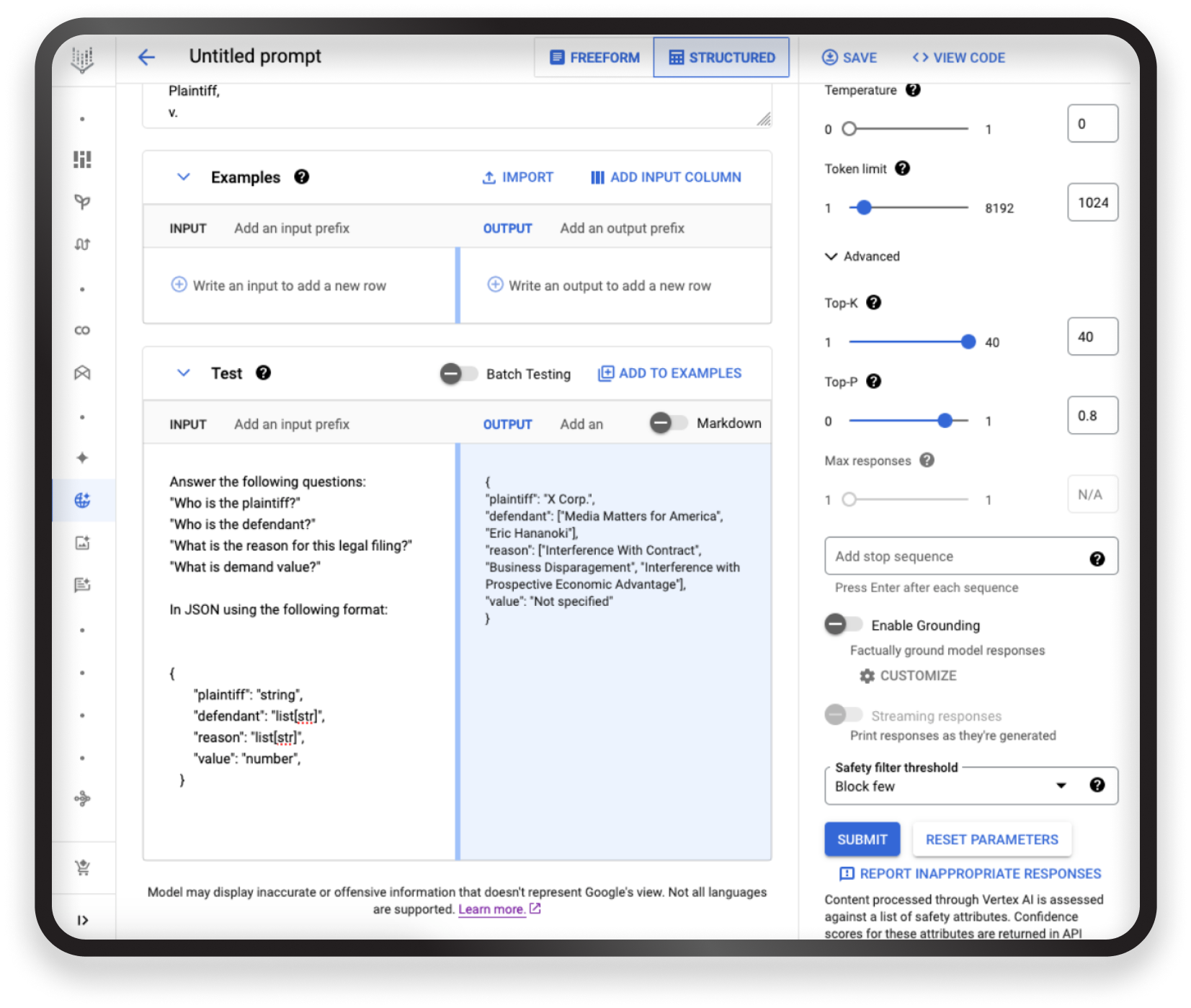
And once again, it responds in the right way. I’m unsure if I’m amazed or scared, but it truly delivers. I have my software running, with part of it even being developed by the LLM. The information is now in a universal language (JSON) and is ready to be integrated into any system.
Expert commentary
Coming from an ML/AI background, I must say that this significantly accelerates research into the possibilities we have now. If I were to use traditional NLP methods and other deterministic techniques, I would spend many hours, and the results wouldn’t be nearly as precise and refined as they are here. Ask me how I know.
While there are some drawbacks when using pre-trained models, especially when trying to run them with three different languages, the accuracy more than compensates for these challenges.
Issues
The result is not production-level software (though it is very close), we have to deal with something that didn’t go so well. The main issues are:
Token limit
Reading documents ‘at large’ can exceed the token limit of the models. For instance, code-bison has an 8k token limit, prompting us to use code-bison-32k, which has 32,000 tokens. This was found to be suitable for all the lawsuit samples we could find.
For production versions, we wouldn’t be able to deploy that as a product due to the token limit. Addressing this challenge might involve incorporating techniques within the method itself, such as using embeddings for text summarization before extraction. Another approach could include reading the text multiple times with overlapping and making several calls to the LLM to see if all the pieces of information are in the chunks until I satisfy my prompts.
These are just a couple of examples of how we can overcome challenges posed by large texts. However, for the majority of cases, the approach taken here proves sufficient.
Code optimization
The code is very crude and passes prompts directly to the model.
Text categorization
Given that our prompts are open and assume the input is a legal paper, everything you upload to the system, it tries to find a ‘plaintiff’ for example, and that is not the case with contracts, or even with novels it tried to find ‘defendants.’ This issue can be resolved using simpler methods, such as basic NLP techniques like Topic Modeling, Intent, and even sentiment analysis.
OCR extraction
With the PDFs being free-form, there are cases where the whole PDF is printed (like our ancestors did), signed by hand, and then scanned and converted into PDF. This is not a common scenario, yet it occurs frequently enough to be noteworthy. Addressing this issue should be a focus in future iterations.
Embedded images
It’s quite common for lawsuits to include appended or embedded images within the text. These images serve as proof, evidence, or illustrations of significant points that legal operators want to emphasize. We don’t account for that, we don’t even try to pass it through the LLM. While the LLM is capable of describing images in detail, it’s not considered relevant at this point since the information extraction doesn’t extend to this level of depth. However, incorporating image analysis as a feature is certainly a possibility for future enhancements.
Conclusion
I hope this guide has given you a glimpse into the world of rapid app development using LLMs. The strategy proved to be a game-changer. Of course, there are hiccups along the way, but nothing that can’t be fixed.
Stay tuned for part 2, where we delve into harnessing LLMs to construct not just an R&D PoC, but a fully-fledged MVP!




